지금까지 SLAM에 대한 이론을 머리에 집어넣으면서 이해가 되지 않는 부분을 예제를 통해 이해가 부족한 부분을 보완하고 채우고 싶은 생각이 항상 있었는데 이번에 단순하게 짜여있는 mono-VO 코드를 찾았습니다. 그래서 이번에 찾은 코드를 한번 리뷰하면서 저 나름대로 오랜만에 코딩을 해보려고 합니다.
The KITTI Vision Benchmark Suite
The KITTI Vision Benchmark Suite
We thank Karlsruhe Institute of Technology (KIT) and Toyota Technological Institute at Chicago (TTI-C) for funding this project and Jan Cech (CTU) and Pablo Fernandez Alcantarilla (UoA) for providing initial results. We further thank our 3D object labeling
www.cvlibs.net
Ground Truth Pose
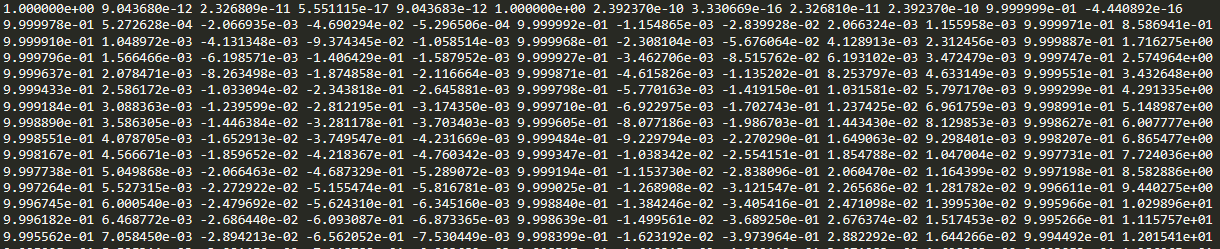
위 그림은 예제코드에서 사용되는 kitti odometry ground truth 데이터입니다. 보기만 해도 벌써 어질어질하지만 데이터가 무엇을 나타내나 검색해보니 1개의 line이 단일 frame에 대한 데이터입니다. KITTI에서는 단일 odometry에 대해 image, lidar, camera calibration, pose 를 세트로 제공하는데 image 또는 lidar의 각각의 frame을 의미합니다. 그리고 한 line에 12개의 data가 있는데 4x4 homogeneous matrix 중 마지막 row가 빠진 데이터입니다.
$$ \begin{bmatrix} r_{1} & r_{2} &r_{3} & x \\r_{4} & r_{5} &r_{6} & y \\r_{7} & r_{8} &r_{9} & z \end{bmatrix}$$
따라서 각 line의 4, 8, 12번째 data를 읽으면 pose를 읽을 수 있습니다.
Camera
cam = PinholeCamera(1241.0, 376.0, 718.8560, 718.8560, 607.1928, 185.2157)
class PinholeCamera:
def __init__(self, width, height, fx, fy, cx, cy,
k1=0.0, k2=0.0, p1=0.0, p2=0.0, k3=0.0):
self.width = width
self.height = height
self.fx = fx
self.fy = fy
self.cx = cx
self.cy = cy
self.distortion = (abs(k1) > 0.0000001)
self.d = [k1, k2, p1, p2, k3]
카메라 캘리브레이션 (Camera Calibration)
카메라 캘리브레이션 (camera calibration)은 영상처리, 컴퓨터 비전 분야에서 번거롭지만 꼭 필요한 과정중의 하나입니다. 본 포스팅에서는 카메라 캘리브레이션의 개념, 카메라 내부 파라미터, 외
darkpgmr.tistory.com
PinholeCamera는 Camera의 intrinsic parameter를 의미하는 것 같습니다. 카메라에 대한 자세한 내용은 모두의 교수님 다크 프로그래머님의 블로그에서 확인하실 수 있습니다.
Gray scale Image scene

Kitti benchmark에서는 3채널 컬러 이미지와 1채널 흑백이미지를 둘다 제공하지만 본 예제에선 흑백을 사용합니다. 참고로 left, right 카메라 2대로 left, right 이미지를 제공하기 때문에 stereo VO/SLAM을 수행할 수도 있습니다.
MONO Visual Odometry
def processFirstFrame(self):
self.px_ref = self.detector.detect(self.new_frame)
self.px_ref = np.array([x.pt for x in self.px_ref], dtype=np.float32)
self.frame_stage = STAGE_SECOND_FRAME
def processSecondFrame(self):
self.px_ref, self.px_cur = featureTracking(self.last_frame, self.new_frame, self.px_ref)
E, mask = cv2.findEssentialMat(self.px_cur, self.px_ref, focal=self.focal, pp=self.pp, method=cv2.RANSAC, prob=0.999, threshold=1.0)
_, self.cur_R, self.cur_t, mask = cv2.recoverPose(E, self.px_cur, self.px_ref, focal=self.focal, pp = self.pp)
self.frame_stage = STAGE_DEFAULT_FRAME
self.px_ref = self.px_cur
def processFrame(self, frame_id):
self.px_ref, self.px_cur = featureTracking(self.last_frame, self.new_frame, self.px_ref)
E, mask = cv2.findEssentialMat(self.px_cur, self.px_ref, focal=self.focal, pp=self.pp, method=cv2.RANSAC, prob=0.999, threshold=1.0)
_, R, t, mask = cv2.recoverPose(E, self.px_cur, self.px_ref, focal=self.focal, pp = self.pp)
absolute_scale = self.getAbsoluteScale(frame_id)
if(absolute_scale > 0.1):
self.cur_t = self.cur_t + absolute_scale*self.cur_R.dot(t)
self.cur_R = R.dot(self.cur_R)
if(self.px_ref.shape[0] < kMinNumFeature):
self.px_cur = self.detector.detect(self.new_frame)
self.px_cur = np.array([x.pt for x in self.px_cur], dtype=np.float32)
self.px_ref = self.px_cur프레임을 처리하는 함수가 3개가 있는데 맨 처음 프레임과 두번째 프레임은 따로 처리해주는 것을 알 수 있습니다.
1. 첫 프레임은 이전 feature가 없기 때문에 feature tracking 없이 key points들만 구해주는 것을 알 수 있습니다. 예제코드에서 사용하는 feature detector는 FAST입니다.


2. 두번째 프레임부터는 Tracking이 필요합니다. 프레임에서 딴 feature가 이전 프레임에서 딴 feature랑 같은 feature인지 체크하는 과정이 필요합니다. 또 두개의 프레임을 이용해 카메라의 위치를 추정할 수 있습니다. Mono-VO 예제코드는 관측값을 이용한 pose 보정없이 순수하게 이미지에서 카메라 위치를 계산해서 Trajectory를 만들었습니다.
3. 이후 프레임은 2.와 동일한데 Feature point가 일정 개수 밑으로 내려가면 다시 feature 들을 찾습니다.

위 Trajectory plot 에서 파란색 경로가 visual odometry trajectory입니다. 다음 포스팅에선 구체적인 구현과 map을 만들때 무엇이 필요한지 알아보도록 하겠습니다.
'SLAM' 카테고리의 다른 글
| iSAM: incremental Smoothing and Mapping (0) | 2022.02.26 |
|---|---|
| PTAM: Parallel Tracking and Mapping for Small AR Workspaces (0) | 2022.01.23 |
| Graph SLAM with Example Code (2) | 2021.10.27 |
| Graph-based SLAM using Pose-Graph (0) | 2021.10.10 |
| EKF SLAM with Example Code (0) | 2021.09.23 |




댓글