What is GPU?

A GPU(Graphic Processing Unit) is a specialized device to accelerate the graphics and image processing. Simply GPU is different from CPU in that it has many cores. So the most important characteristic of GPU is parallelism. To fully utilize the device, we have to know the basic architecture and concept.
Why GPU?
The GPU is ofter used in applications that require a lot of computation, such as physics simulation, or in computer vision.
GPU Architecture
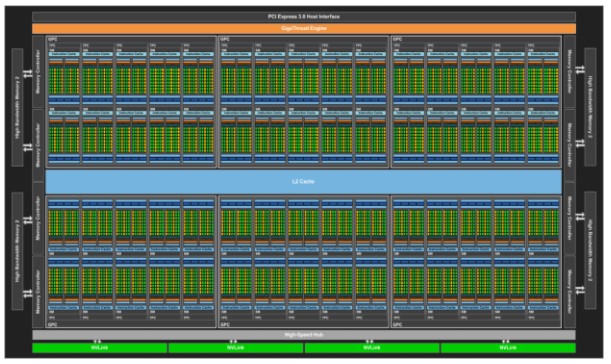
GPU Memory
To maximize the GPU's parallelism, we need enough data to access and compute simultaneously. For efficient data access, GPU has an independent memory hierarchy.
- Global memory
- L1/L2 cache
- Shared memory
- Register File
Global memory is the lowest memory in the hierarchy, which have biggest capacity and longest access latency. To launch CUDA kernal, the data must be copied to GPU's global memory from the host program. Accessing global memory is very costly, so utilizing memorys in upper layer is important to improve the performance.
L1/L2 cache
GPU has L2 cache that is shared by SM(Streaming Multiprocessor). Cache is not a programmable memory, but still very important for high performance. Since the L2 cache is shared resource shared by SMs, there memory contention may occur under certain circumstances. It is a general idea to maximize TLP(Thread Level Parallelism) on GPUs, but for this reason, profiling is necessary if adequate occupancy is filled. Unlike the L2 cache, the L1 cache is very fast because it inside the SM.
Shared Memory
Basically, in the GPU kernel, threads do not share memory and load the data needed in the register file. If the program requires data sharing between threads, we can use shared memory using __shared__ specifier. Shared memory is allocated per thread block, so all threads in the threads in block have access to the same shared memory. However, because the execution order of the threads in the thread block is not determined,

To avoid race condition, nvidia provides a barrier primitive __syncthreads().
Processors
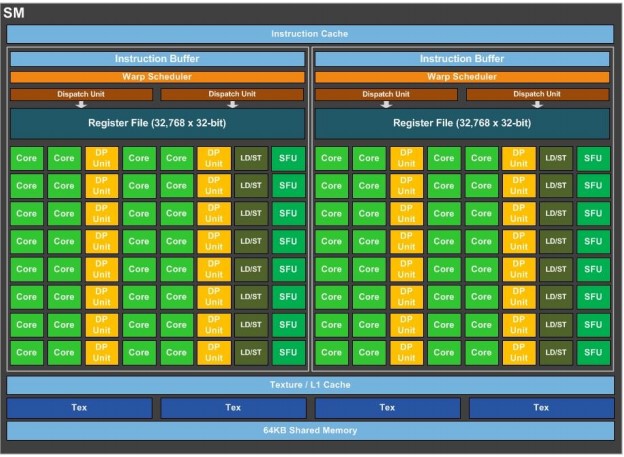
The strength of a GPU's parallelism comes from its large number of cores. There are 2 types of cores called SM(Streaming Multiprocessor), and SP(Streaming Processor). Each cores are allocated for different execution unit;
SM for thread block scheduling; SP for thread execution.
'GPU & CUDA' 카테고리의 다른 글
| Sparse Matrix Format (0) | 2021.07.06 |
|---|---|
| Accelerating Matrix Multiplication Using GPU (0) | 2021.06.27 |
| CUDA (0) | 2021.06.25 |



댓글