CUDA
The CUDA is a parallel computing platform and application programming interface model supported by NVIDIA. CUDA programmers can program general purpose parallel program using C/C++ like language. CUDA Toolkit includes many functions such as libraries for GPU accelerating, monitors, profilers and etc. So if you want to customize or optimize your GPU application, it is very advantageous if you understand and use CUDA.
CUDA Kernal Hierarchy
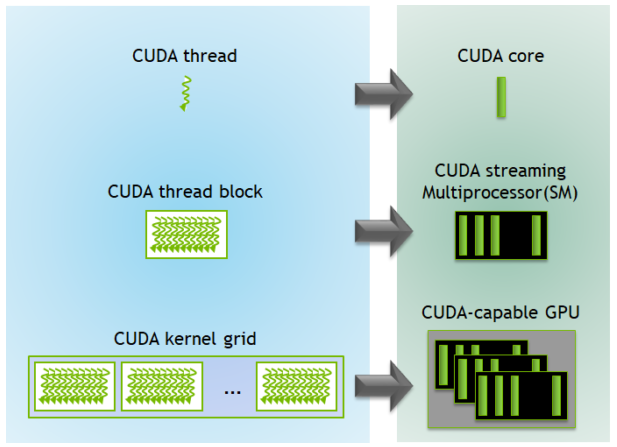
CUDA kernel consists composed of grid, thread block, thread.
- Grid : A set of all thread blocks and is the CUDA kernel itself
- Thread Block : A set of threads, usually number of threads with an exponent of 2
- Thread : The smallest unit consists the kernel.
To accelerate an application using the GPU, the necessary data must first be copied to the GPU. Therefore, a typical GPU kernel pipeline consists of allocation, copy(host to device), execution, copy(device to host), free.
When the kernel is launched, grid is allocated a GPU.
Then thread blocks in grid are scheduled in the SM. The number of thread blocks that can be loaded into a sign SM depends on the resource required by the block, for example, the number of threads or the size of shared memory. Once the block is scheduled, is not reallocated to another SM(Streaming Multiprocessor).
When threads are executed by SP(Streaming Processor a.k.a CUDA core), they are executed in a unit of 32 thread called warp. Warp is the basic scheduling unit, and all threads in the warp are executed in lock-step.

Since the volta architecture, GPUs support independent scheduling, but it is better to think threads are executed in lock-step.
'GPU & CUDA' 카테고리의 다른 글
| Sparse Matrix Format (0) | 2021.07.06 |
|---|---|
| Accelerating Matrix Multiplication Using GPU (0) | 2021.06.27 |
| GPU Architecture (0) | 2021.06.20 |



댓글