직장을 다니다보니 이전에 봤던것들도 기억이 안나서 정리를 다시 해보려고 합니다.
다양한 네트워크가 쏟아져나오면서 컨볼루션 연산도 기본적인 stride, filter size 등을 조절하는 것 뿐만 아니라 그룹을 지어 하는 Grouped Convolution 등 여러 방안들이 제안되었습니다. 이런 제안들 중 오늘 정리하려는 연산은 1x1(Point-Wise Convolution) 입니다.

1x1 Convolution을 생각하면 이걸 왜 하느냐에 대한 의문이 생길 수 있습니다. 첫 그림처럼 1x1 Convolution은 scalar 곱이나 마찬가지이기 때문입니다. Filter의 채널이 증가해도 output channel은 filter의 개수가 결정하기 때문에 1채널짜리 output이 생기게됩니다. 즉 Filter의 수를 조절함으로써 output channel의 크기를 조절할 수 있다는 것입니다.
이 개념은 Inception network에서 사용됩니다.
Inception Network
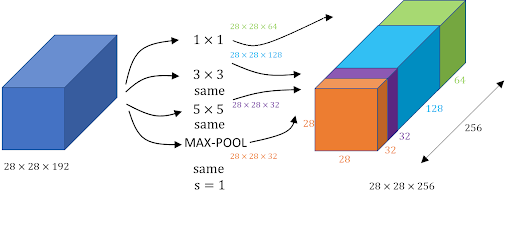
GoogLeNet에서 Convolution의 기본적인 Inception Module은 위와 그림과 같습니다. 다양한 사이즈의 Filter 의 결과를 concat 해놓은 형태라고 볼 수 있죠. 개념적으로는 어렵지 않습니다. 하지만 만약 현재 나의 모델이 real-time, real-time은 아니더라도 좀 더 빨랐으면 좋겠다라고 생각한다면 Computational Cost를 생각해야합니다.
위 그림의 5x5 Conv를 진행한다고 생각하면 Computational cost는 28x28x32x5x5x192가 됩니다. 이는 단일 Inception 모듈중에서도 일부이기 때문에 적지 않은 비용입니다. GoogLeNet 은 이를 1x1 Conv로 해결합니다.

위에서 언급했듯이 1x1 Conv는 Output Channel의 수를 조절하는데 사용될 수 있습니다. 따라서 Input Channel이 192더라도 1x1를 거쳐 16 Channel로 만든 후, 우리가 원하는 5x5 Conv를 진행하면 Computational Cost는 \(28\times28\times192\times1\times1\times192\times16 + 28\times28\times16\times5\times5\times16\times32\), 약 \(124M\)로 10배가 줄게됩니다.
이렇게 비용절감을 위한 1x1 Conv Layer를 Bottleneck Layer라고 부르기도 합니다.
'Vision' 카테고리의 다른 글
| SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (2) | 2022.01.19 |
|---|---|
| SENet(Squeeze-and-Excitation Networks) (0) | 2022.01.05 |
| Pseudo-LiDAR from Visual Depth Estimation:Bridging the Gap in 3D Object Detection for Autonomous Driving (0) | 2021.11.21 |
| Introduction - Attention (0) | 2021.10.31 |
| Complex-YOLO: Real-time 3D Object Detection on Point Clouds (0) | 2021.09.12 |




댓글